
WeKnora:企业 RAG 的关键,不是把文档丢进向量库
WeKnora 适合把企业文档接入、解析切分、混合检索、Agent 问答、Auto-Wiki 和部署监控串成可追溯知识系统。
NBAI.club 编辑部

WeKnora:企业 RAG 的关键,不是把文档丢进向量库
摘要:WeKnora 是腾讯开源的企业级 AI 原生知识基础设施项目,面向 RAG、Agent、知识库和 Auto-Wiki 场景。它真正值得关注的地方,不是“能不能问文档”,而是能否把文档来源、解析切分、混合检索、引用追踪、Agent 工具调用和部署监控串成可追溯系统。企业做知识库,难点从来不只是向量化。
很多团队第一次做企业知识库,会把重点放在模型和向量数据库上:把 PDF、Word、Markdown、网页资料导入,做 embedding,再接一个聊天界面。但上线后问题很快出现:回答引用不到原文,权限边界不清楚,文档更新后结果不一致,复杂问题检索不到关键段落,业务方不知道该信不信。
WeKnora 的价值在于把这些问题放到工程流程中处理。它围绕多源文档接入、语义检索、关键词检索、Agent 问答、知识沉淀和部署运行,提供了一套更接近企业落地的开源路径。
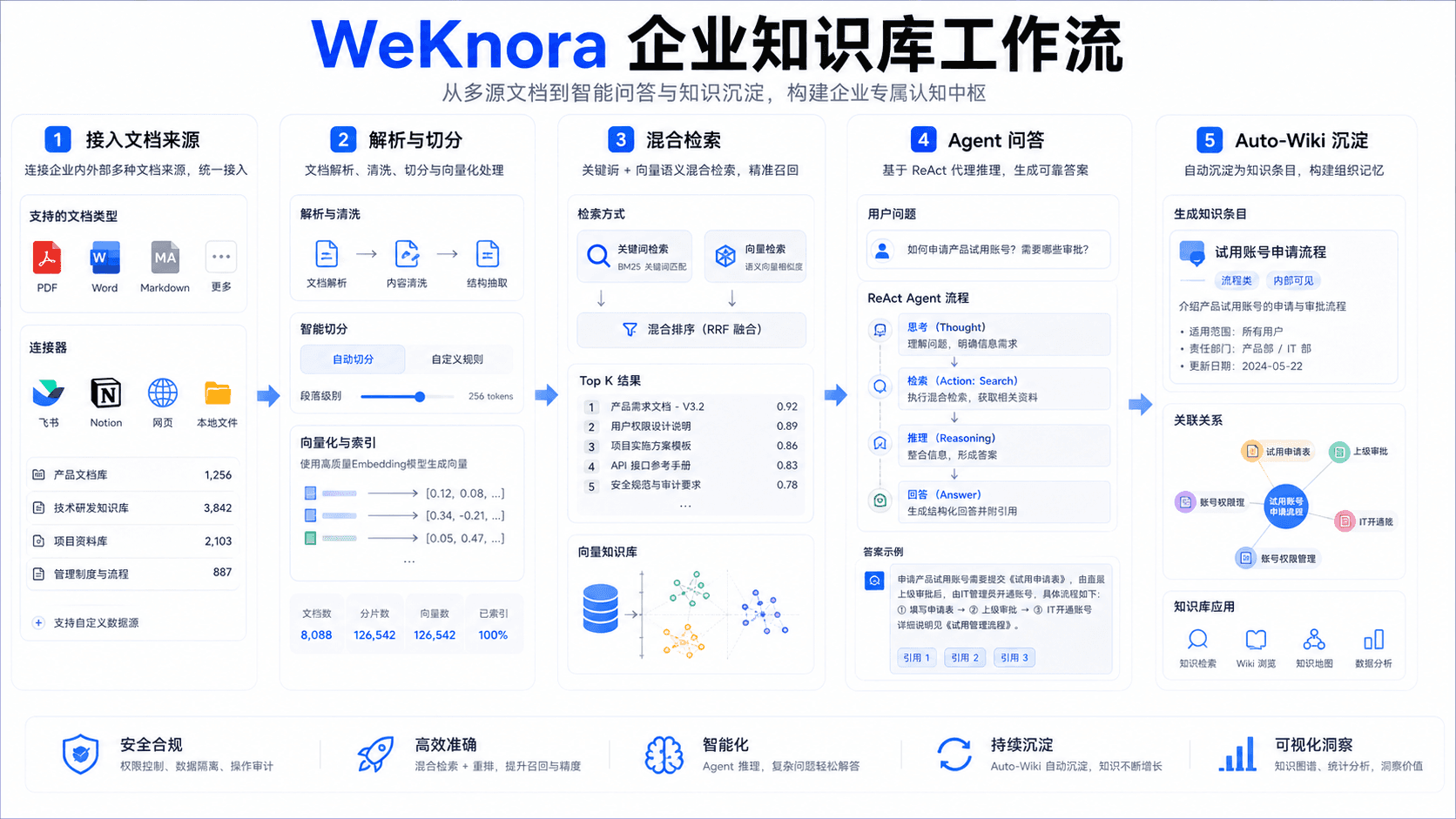
第一步:先治理文档来源
企业 RAG 的第一步不是切分,而是确认文档来源。政策制度、产品文档、客服话术、研发手册、合同模板和会议纪要的可信等级不同,更新频率也不同。如果把所有资料无差别导入,知识库会很快变成“看似全、实际乱”。
