
MotionAgent:AI 动作视频生成的关键,不是只写一段提示词
MotionAgent 适合研究动作、轨迹和镜头控制在 AI 视频生成中的作用,关键是先拆动作、再生成、再逐段质检。
NBAI.club 编辑部

MotionAgent:AI 动作视频生成的关键,不是只写一段提示词
摘要
MotionAgent 是 ModelScope 相关的开源 AI 视频与动作生成项目,GitHub 和论文资料展示了它围绕动作描述、轨迹规划、视频生成和多智能体协作的思路。对内容团队和技术团队来说,它的价值不是“输入一句话直接出大片”,而是把脚本拆解、动作控制、镜头设定、生成结果和人工质检串成一条可复用流程。
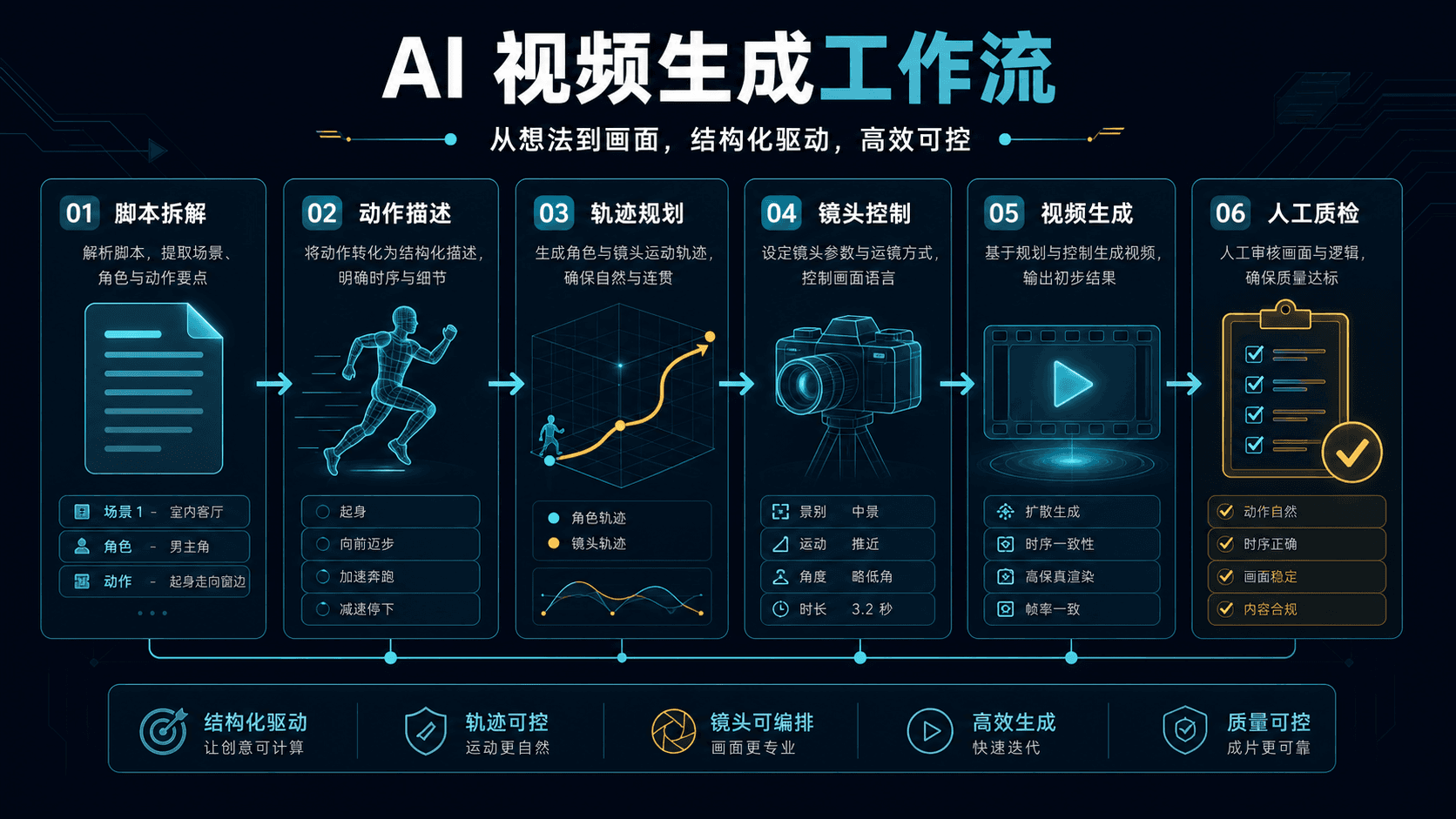
先控制运动,再追求画面
很多 AI 视频生成失败,并不是画质不够,而是运动不清楚。人物该往哪里走、镜头该怎么移动、动作持续多久、前后帧是否连贯,这些问题如果没有提前定义,模型很容易生成漂亮但不可用的片段。
MotionAgent 这类项目的启发在于:视频生成不应只依赖一句自然语言提示词,而要把动作、轨迹和镜头拆开表达。对于短视频、动画预演和概念分镜来说,先明确运动关系,再生成画面,比一开始追求视觉风格更可靠。
例如“一个人跑向镜头”不是足够的描述。更可控的写法是:人物从远处进入画面,沿直线向前跑,镜头轻微后退,持续 4 秒,背景保持稳定。这样的动作信息更适合进入后续生成和验收。
