编辑内容工具教程
Kimi Claw:让 Agent 跑起来之前,先把权限和复盘设计好
Kimi Claw 适合把 Kimi 模型、云端设置、技能库和 Agent 工作流结合起来,关键是先设计任务边界、权限范围、人工确认和复盘机制。

Kimi Claw 适合把 Kimi 模型、云端设置、技能库和 Agent 工作流结合起来,关键是先设计任务边界、权限范围、人工确认和复盘机制。
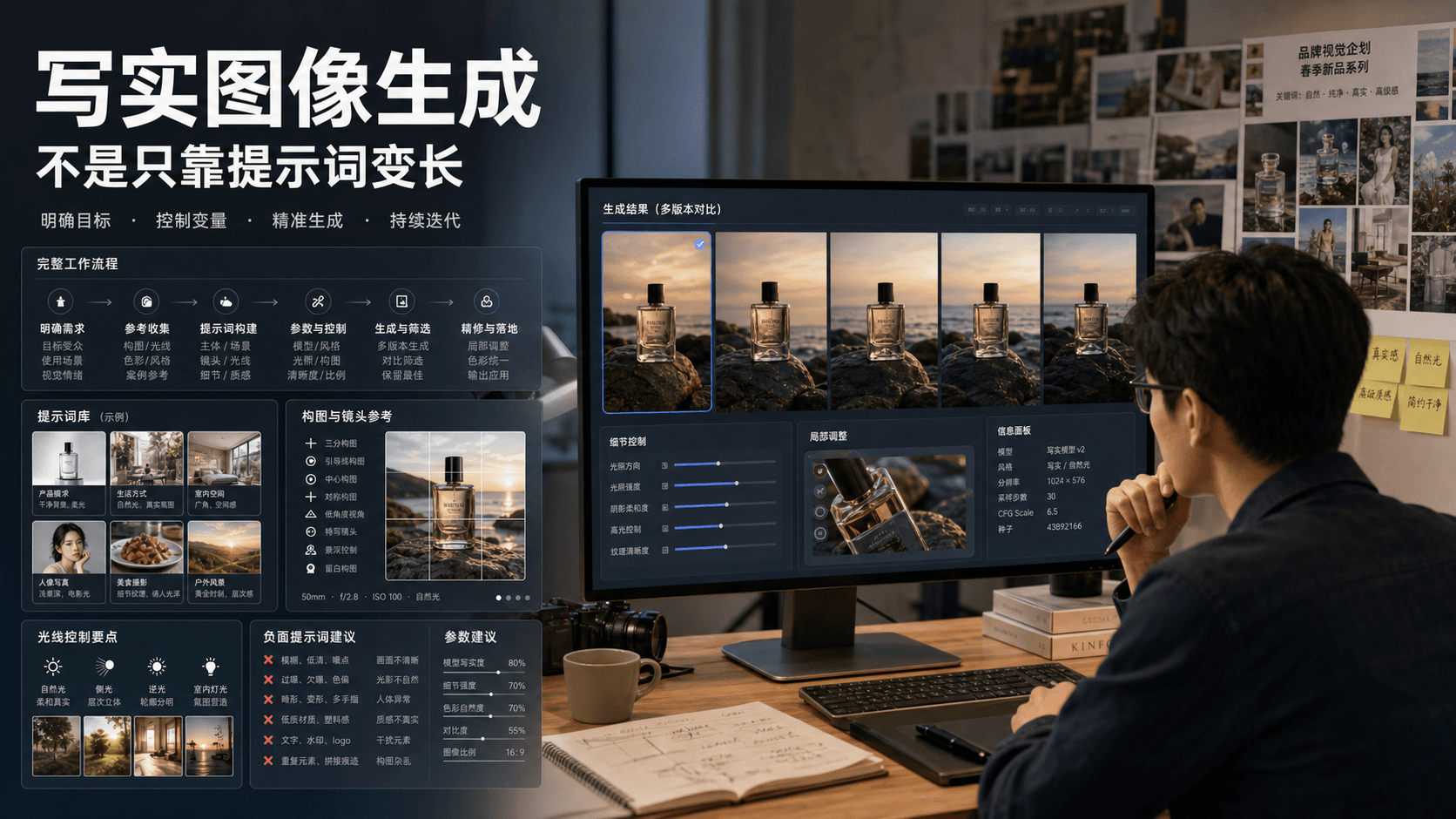
Lexica Aperture 适合快速探索写实图像方向,关键是先定义用途、拆解摄影语言、控制构图光线并做发布前复核,而不是把提示词越写越长。
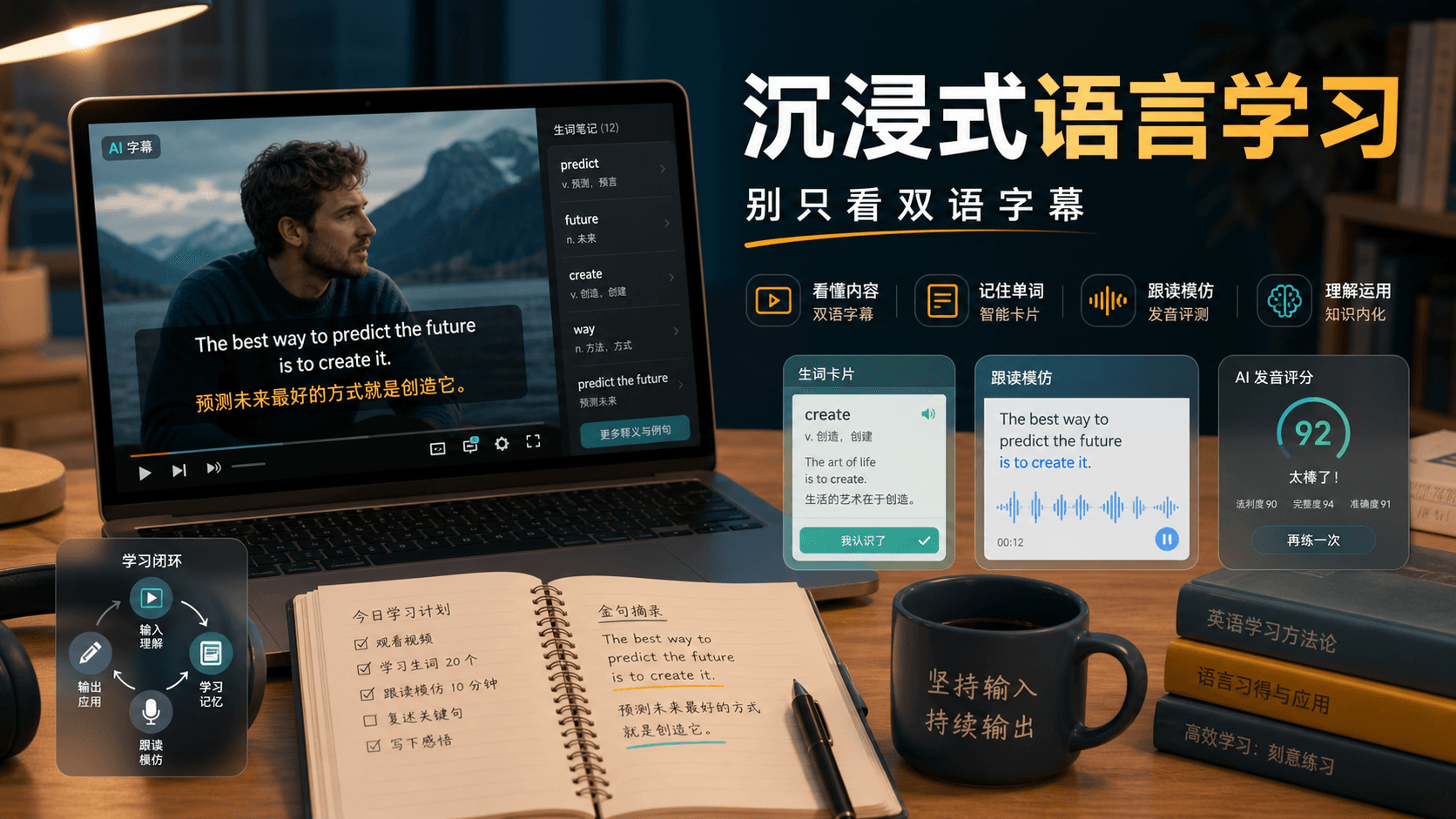
Trancy 适合把 YouTube、Netflix、网页和课程材料变成语言学习闭环,关键是从双语字幕、逐句精听、生词卡片、跟读模仿走到间隔复习,而不是被动追剧。
AI Face Swap 可以快速完成图片、视频或 GIF 换脸,但在真实内容生产中,授权、隐私、冒充风险和平台标注比生成效果更重要。
Kilo Code AI 适合把需求拆成任务、选择模型、生成计划、执行代码改动并配合测试复核,关键是让 Agent 编程可控。
GPTZero 适合做 AI 文本风险初筛,但检测分数不能直接变成判决。更稳妥的做法是结合高亮证据、写作过程、草稿材料和人工复核,把检测结果放进可解释的治理流程。
Monica 把搜索、总结、翻译、写作和多模型能力放进浏览器侧边栏。它适合高频处理网页、邮件、视频和资料的用户,但团队使用前必须先设定隐私、权限和复核边界。
AutoGen 已进入维护模式后,存量多智能体项目不应盲目扩展。更稳妥的做法是盘点依赖、限制权限、补齐评测与回滚,再决定保留、过渡或迁移到新的 Agent 框架。
DeepSeek-TUI 已向 CodeWhale 迁移,定位也从 DeepSeek 专用终端助手扩展为多模型终端 Coding Agent。文章梳理迁移路径、配置兼容、安全边界和真实代码库里的任务闭环。
Semantic Scholar 不只是论文搜索入口,更适合被当成研究工作的第一层筛选器:从种子论文、引用网络、相关论文和 API 数据进入,把文献发现整理成可复核的证据管理流程。