编辑内容工具教程
YouTube Summary with ChatGPT:视频摘要的关键,不是少看一遍视频
YouTube Summary with ChatGPT 适合把长视频拆成摘要、时间戳和笔记线索,但正式引用前仍要回到原片复核语境。

YouTube Summary with ChatGPT 适合把长视频拆成摘要、时间戳和笔记线索,但正式引用前仍要回到原片复核语境。
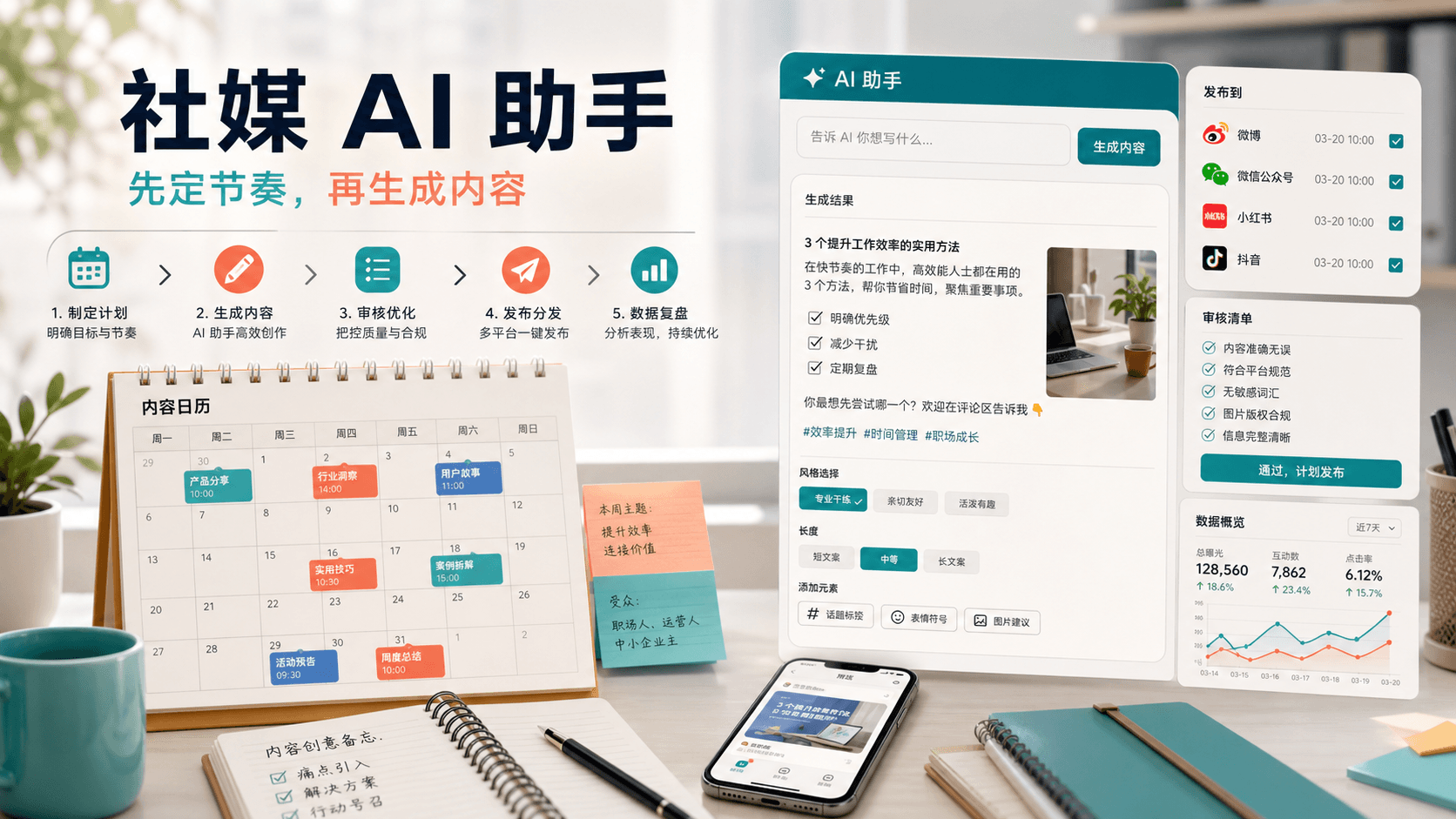
Buffer AI Assistant 更适合放进社媒内容节奏、平台改写、人工审核、排程和复盘闭环,而不是当成自动发帖机器。
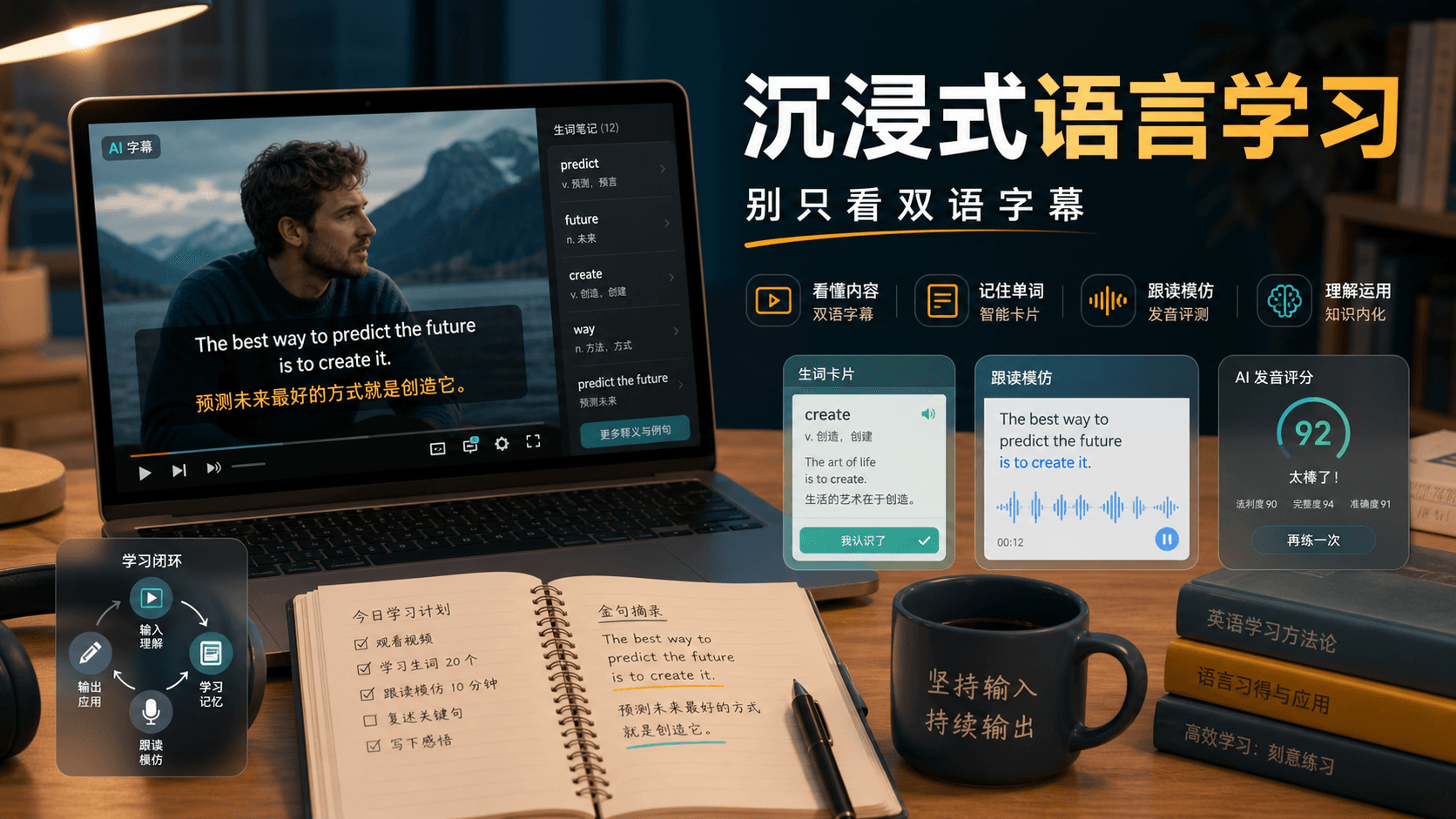
Trancy 适合把 YouTube、Netflix、网页和课程材料变成语言学习闭环,关键是从双语字幕、逐句精听、生词卡片、跟读模仿走到间隔复习,而不是被动追剧。
Originality.AI 更适合做发布前内容风险雷达:AI 检测、抄袭检查和可读性结果应触发人工复核,而不是直接决定文章命运。
GPTZero 适合做 AI 文本风险初筛,但检测分数不能直接变成判决。更稳妥的做法是结合高亮证据、写作过程、草稿材料和人工复核,把检测结果放进可解释的治理流程。
CodeGeeX 适合放进 IDE 内的日常开发流程:代码补全、解释、翻译、测试生成和人工复核。它真正的价值不是替开发者少思考,而是减少上下文切换,并让 AI 输出进入可验证的工程流程。
Monica 把搜索、总结、翻译、写作和多模型能力放进浏览器侧边栏。它适合高频处理网页、邮件、视频和资料的用户,但团队使用前必须先设定隐私、权限和复核边界。
Semantic Scholar 不只是论文搜索入口,更适合被当成研究工作的第一层筛选器:从种子论文、引用网络、相关论文和 API 数据进入,把文献发现整理成可复核的证据管理流程。
Groq 的核心价值不是又一个聊天模型入口,而是面向开发者的低延迟 LLM 推理 API。它适合需要快速响应、流式输出、语音转文字、视觉理解和模型服务接入的应用,但生产上线必须同时处理稳定性、限流和成本。
Connected Papers 不是普通论文搜索框,而是一个围绕种子论文生成相似论文图谱的研究工具。它适合用来发现研究脉络、先前工作、后续研究和综述线索,但不能替代读原文、核验方法和检查引用。
HeyGen 不只是数字人视频生成器,它更适合被放进企业视频生产流程里:先确认脚本、肖像授权、复核流程和发布边界,再用 AI 数字人、视频翻译和 API 提升生产效率。
ElevenLabs 不只是文本转语音工具,它把配音、多语言本地化、声音资产、API 和语音 Agent 放进同一条链路;真正成熟的用法是管好脚本、授权、校对、成本和上线规则。
Hugging Face 的价值不只是找模型,而是把模型、数据集、Spaces、推理服务、企业协作和成本治理串成可复用的 AI 工程工作流。
Canva AI 的价值不止是文生图,而是把 Dream Lab、Magic Media、模板、品牌风格和多尺寸导出串成内容团队可复用的设计生产流程。