OpenHuman:本地 AI 助手的关键,不是把模型搬到电脑里
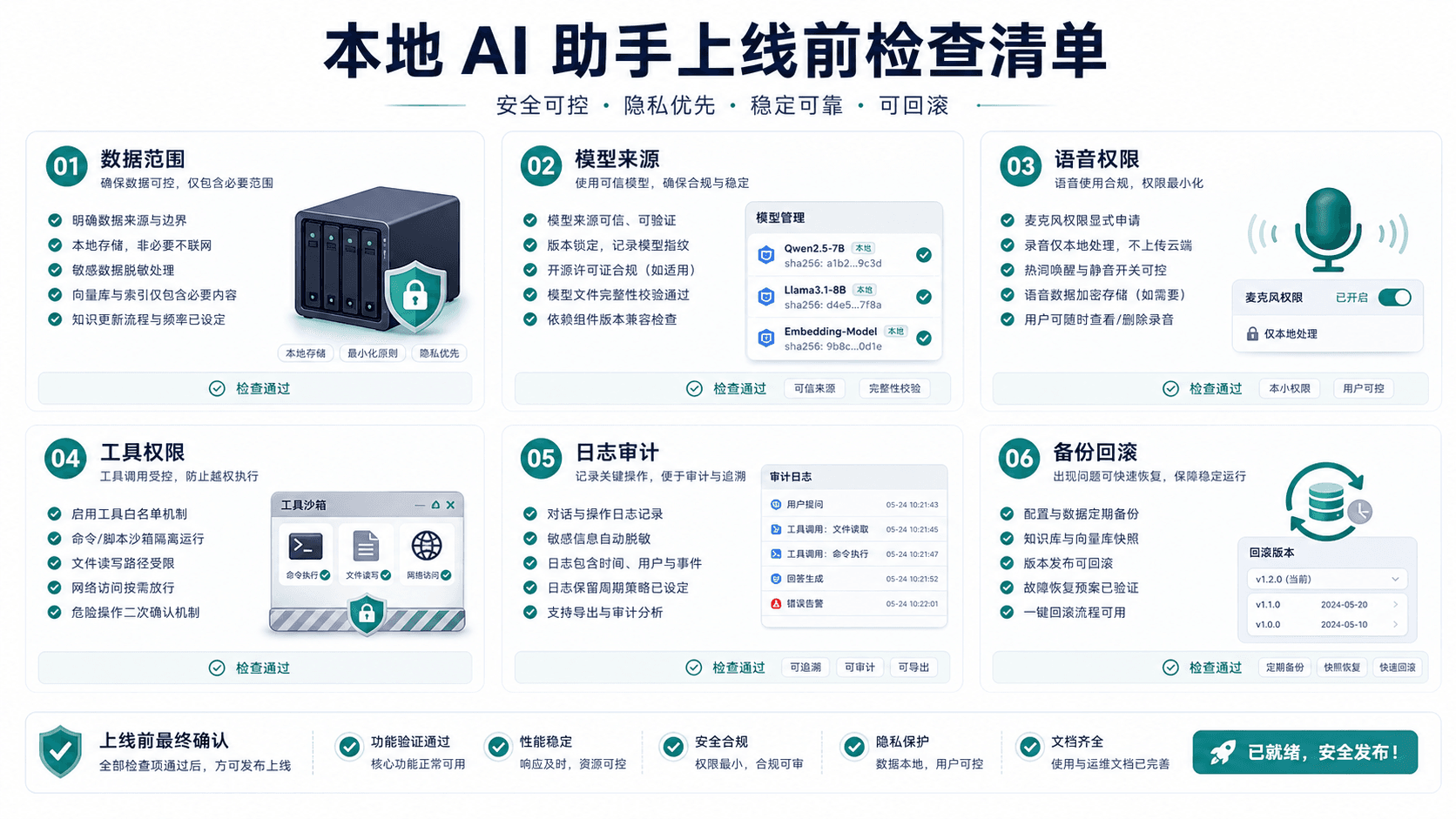
OpenHuman 适合验证本地 AI 助手、语音和 Agent 工作流,但真正关键是数据范围、模型来源、工具权限和日志回滚。
NBAI.club 编辑部

OpenHuman:本地 AI 助手的关键,不是把模型搬到电脑里
摘要:OpenHuman 是一个面向本地部署 AI 助手的开源项目,适合想把对话、Agent、语音和本地模型放在自己环境里的开发者和团队。它真正要解决的不是“离线也能聊天”,而是数据范围、模型来源、语音权限、工具调用、日志审计和回滚机制。只要涉及私人文档、内部流程或语音交互,本地部署只是第一步,权限设计才是核心。
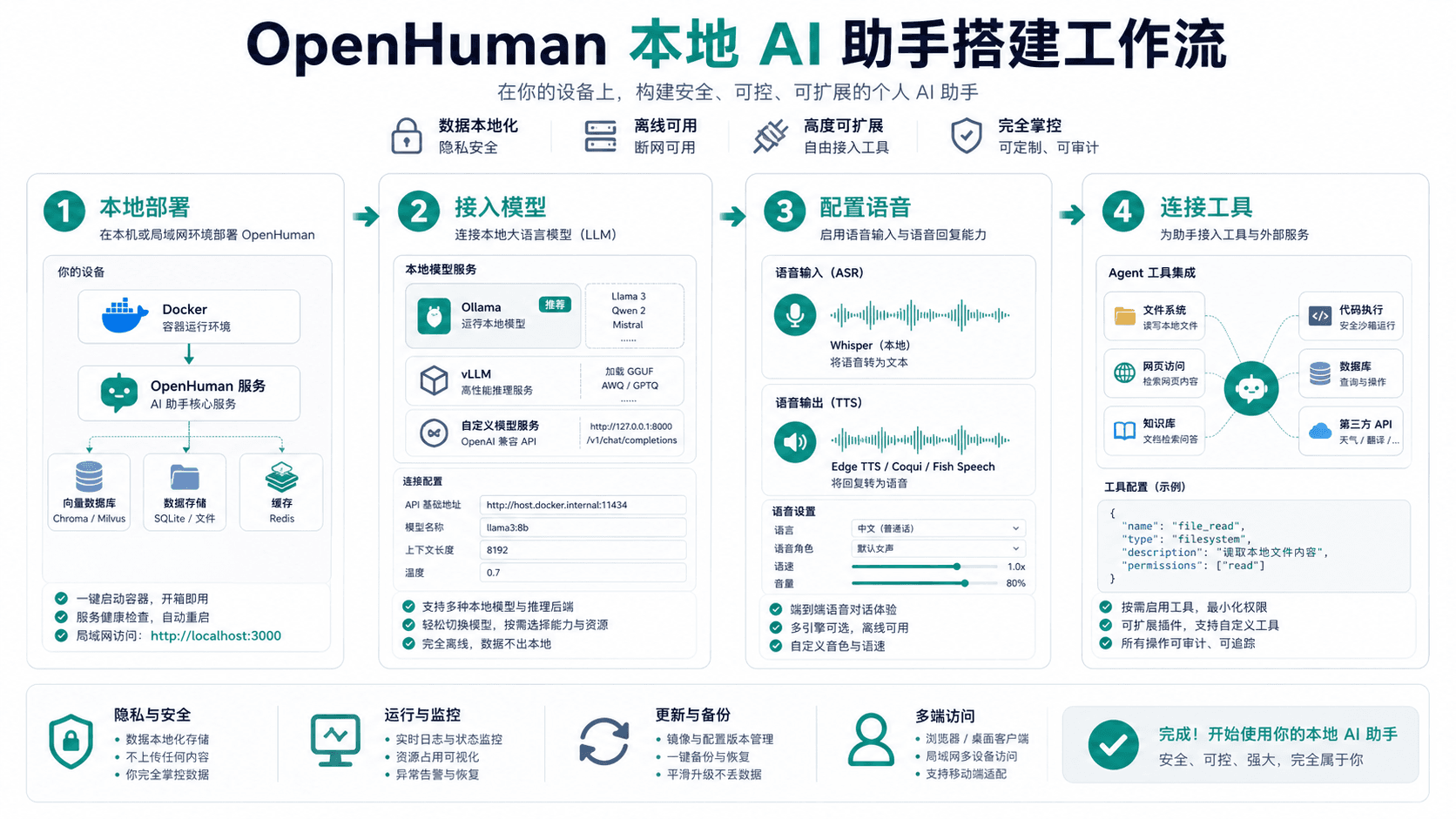
OpenHuman 官方 GitHub 仓库提供 README、代码和部署说明,是判断项目能力的主要来源。项目描述围绕本地 AI、人机交互、语音和 Agent 体验展开,并提到 ElevenLabs 等语音选项。对中国用户来说,这类工具的吸引力很明显:敏感数据不想交给外部平台,团队希望在本地或自有服务器上构建一个可控的 AI 助手。
但本地部署并不自动等于安全。只要 AI 助手能读取文件、调用工具、听取麦克风或生成语音,它就需要明确边界。否则,本地助手可能从“隐私友好”变成“权限过大的内部风险”。
先定义数据范围
部署 OpenHuman 前,第一件事不是选择模型,而是定义它可以访问哪些数据。个人用户可以从低风险目录开始,例如公开笔记、说明文档和测试数据。企业用户则要区分公开资料、内部资料、客户数据、凭证、财务和合同。
最小权限原则非常重要。不要一开始就让本地助手读取整个硬盘或整个共享盘。更稳妥的方式是创建专门的资料目录,把允许访问的文件复制进去,再根据使用情况逐步扩展。
如果 AI 助手用于个人知识库,也要保留删除和重建索引的能力。知识库一旦包含过期、错误或敏感内容,模型回答就可能污染决策。数据范围必须可审计,而不是靠“我记得放了什么文件”。