Lorka AI:多模型工作台的关键,不是把所有模型都订一遍
Lorka AI 适合把多模型聊天、搜索、PDF 分析和图像工具集中到一个工作台,关键是模型分工、成本控制和流程沉淀。

Lorka AI:多模型工作台的关键,不是把所有模型都订一遍
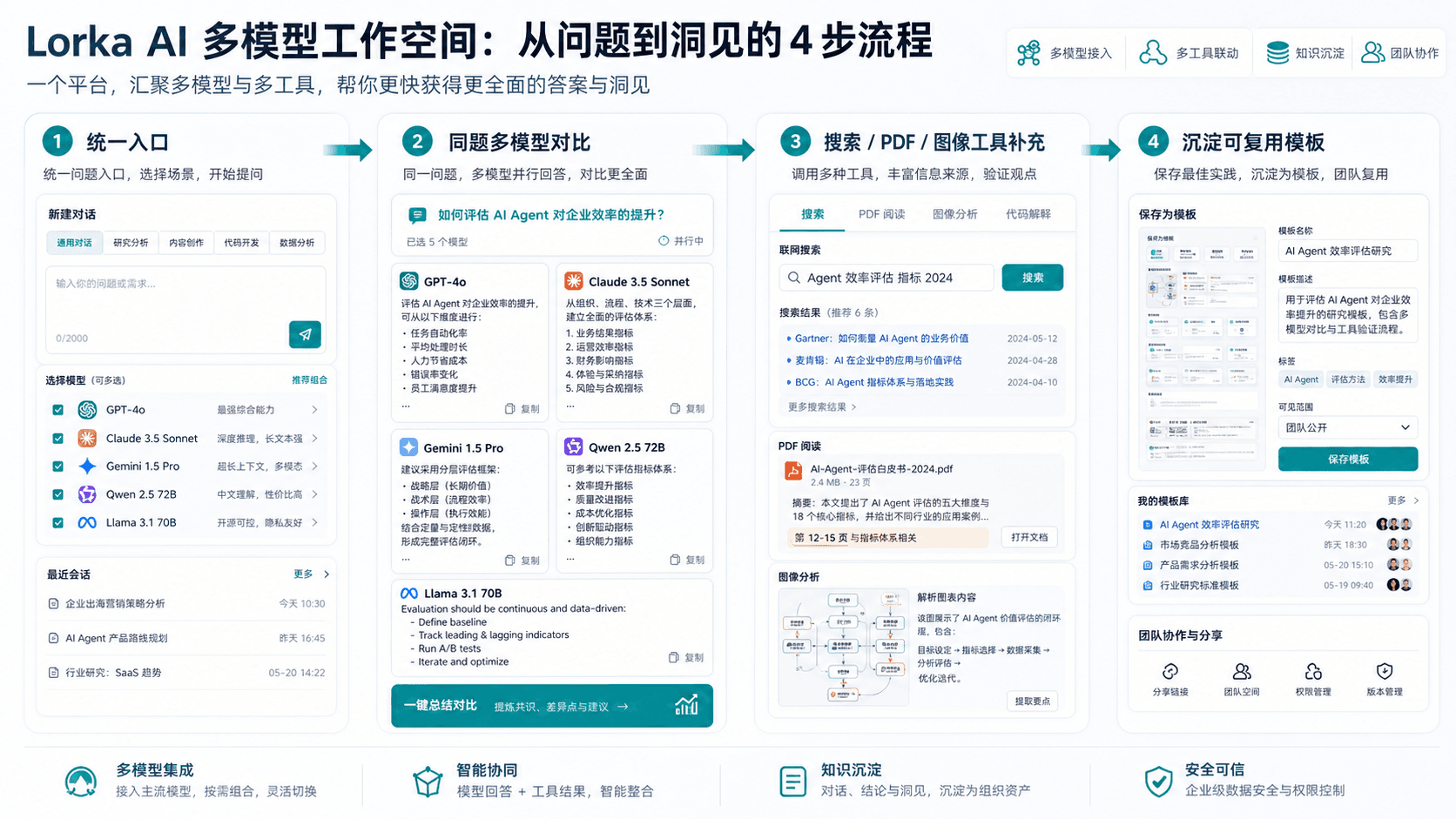
摘要:Lorka AI 把 OpenAI、Anthropic、Google、xAI、DeepSeek、Moonshot、Qwen 等模型入口,以及搜索、PDF 分析、图像工具等能力放在同一个工作台里。对普通用户和小团队来说,它真正要解决的不是“我能不能同时用更多模型”,而是如何给不同任务分配合适模型、控制订阅成本、减少上下文切换,并把好用的提示词和流程沉淀下来。
为什么多模型入口会变成真实需求?
过去很多人只使用一个聊天机器人,问题也很简单:选 ChatGPT、Claude、Gemini 还是 DeepSeek?但实际工作一段时间后,单一模型很快会遇到边界。写作可能更依赖长文本风格,代码需要逻辑和调试能力,资料检索需要联网信息,图片任务又是另一套能力。于是用户开始同时开多个网页、管理多个订阅、复制同一段提示词到不同模型,再手动比较结果。
Lorka AI 这类多模型工作台的价值就在这里。它把多个模型和工具集中到一个界面,降低切换成本。官方页面显示,Lorka 提供多种聊天模型入口,并围绕 AI 搜索、PDF 分析、图像工具和知识内容组织了产品能力。对中国用户来说,这类工具尤其适合需要长期对比模型输出的场景,例如营销文案、研究摘要、代码解释、竞品分析、报告改写和素材生成。
但要注意,多模型工作台不是“模型越多越好”。如果没有使用规则,用户只会从一个混乱的浏览器标签页,换到另一个混乱的聚合面板。
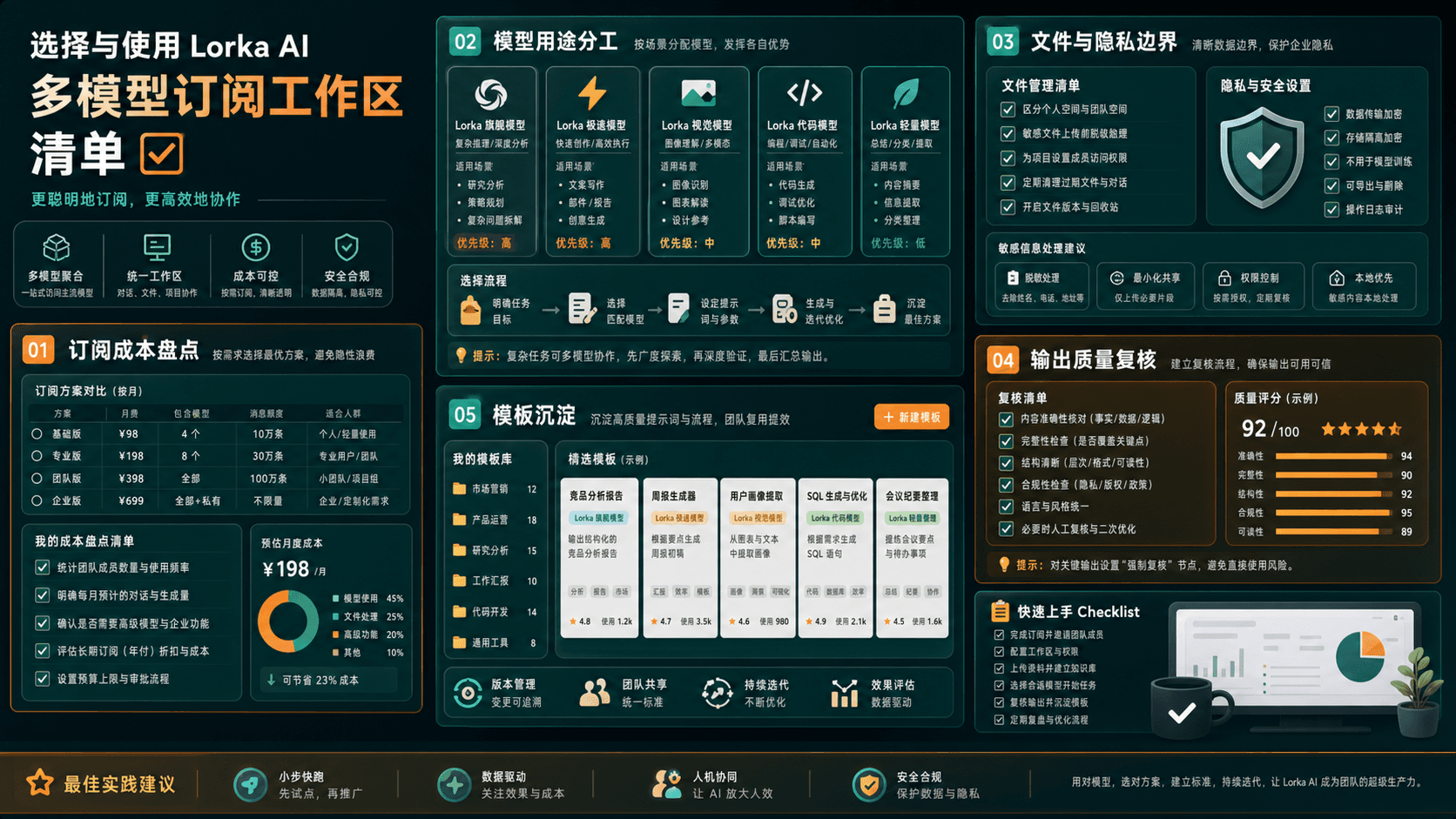
第一步:先给模型分工,而不是随机切换
最有效的做法,是把模型按任务分工。比如,长文写作和语气调整可以用一类模型,代码解释和结构化推理用另一类模型,快速搜索和事实核对用带检索能力的入口,PDF 或长资料则进入文档分析流程。这样做的好处是,团队不需要每次都重新思考“今天用哪个模型”,而是按任务类型选择。