Exa AI:给 Agent 接入真实网络上下文,关键不是搜索更多,而是检索更准
Exa AI 适合给 RAG、AI Agent、研究助手和内容分析产品接入联网检索能力;真正成熟的用法是先定义检索边界,再把可追溯的网络上下文交给模型。

Exa AI:给 Agent 接入真实网络上下文,关键不是搜索更多,而是检索更准
摘要:Exa AI 适合给 RAG、AI Agent、研究助手和内容分析产品接入联网检索能力。它的核心价值不是替代搜索引擎首页,而是通过语义搜索、网页内容提取、Answer API 和结构化结果,让模型拿到更适合生成答案的网络上下文。真正成熟的用法,是先定义检索边界,再把结果交给模型,而不是让 Agent 无限制上网。
现在很多 AI 应用都会遇到同一个问题:模型本身会推理、会写作、会对话,但它不知道最新网页、公司动态、论文、产品文档和行业资料。于是团队开始给应用加联网搜索,或者把搜索结果接进 RAG。但如果只是把普通搜索结果塞给大模型,效果经常不稳定:来源太杂、正文抓不到、重复内容多、时间信息不清、模型引用了看起来相关但事实不可靠的网页。
Exa AI 的定位正好切在这个问题上。它不是给普通用户做一个搜索首页,而是面向开发者和 AI 应用提供搜索 API、内容提取和 Answer 能力,让 Agent、研究助手、知识库系统和内容产品能拿到更适合机器处理的网络信息。换句话说,它更像是 AI 应用的“联网检索层”,而不是传统意义上的搜索入口。
对中国开发者来说,Exa AI 值得关注的原因也很直接:如果你在做 AI 搜索、行业情报、研究助手、销售线索发现、竞品监控、论文与网页检索、内容生成工具,单纯依赖模型内置知识一定不够;但自己搭爬虫、索引、去重、正文抽取和来源质量评估,又很重。Exa 提供的是一条更短的工程路径。
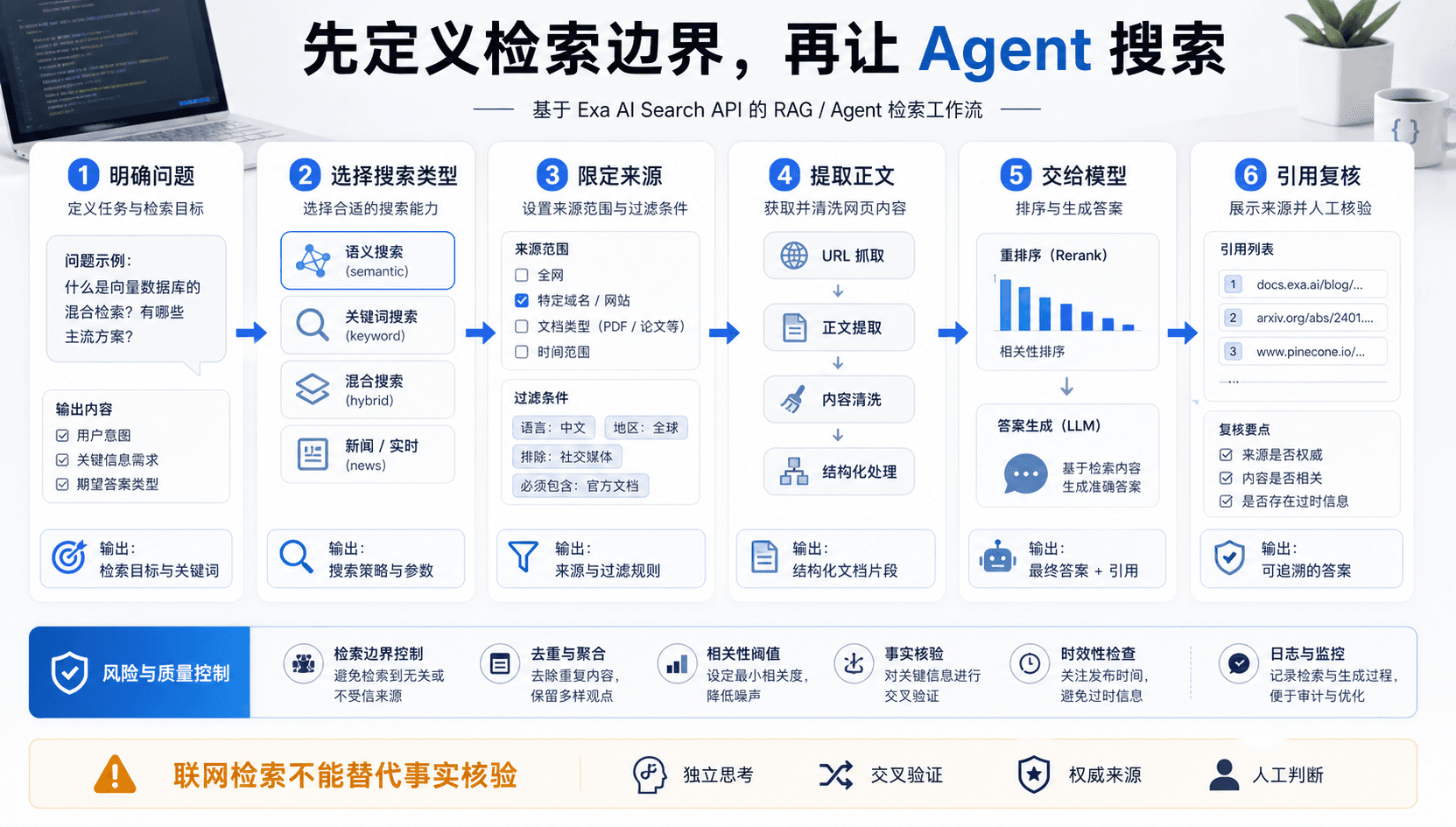
Exa 解决的不是“能不能搜索”,而是“搜索结果能不能进模型”
普通搜索面向人。搜索结果页给你标题、摘要和链接,人会自己判断哪个可信、哪个过时、哪个只是 SEO 内容。AI Agent 不一样。它需要的是可被程序处理的结构化结果、正文内容、元数据、来源链接,以及足够稳定的排序。否则模型会把不完整、重复或低质量信息当成上下文,最后生成一个看似流畅但事实不稳的答案。
Exa 的 Search API、Get Contents、Answer API 这些能力,核心价值在于把“找网页”变成“给模型准备上下文”。Search API 负责根据查询返回相关网页,Get Contents 可以进一步获取网页正文内容,Answer API 则面向带来源的回答场景。官方文档也把这些能力放在开发者 API 语境里,而不是普通搜索产品语境里。