AnythingLLM:把私有知识库做成 AI 工作台,关键不是“能聊天”
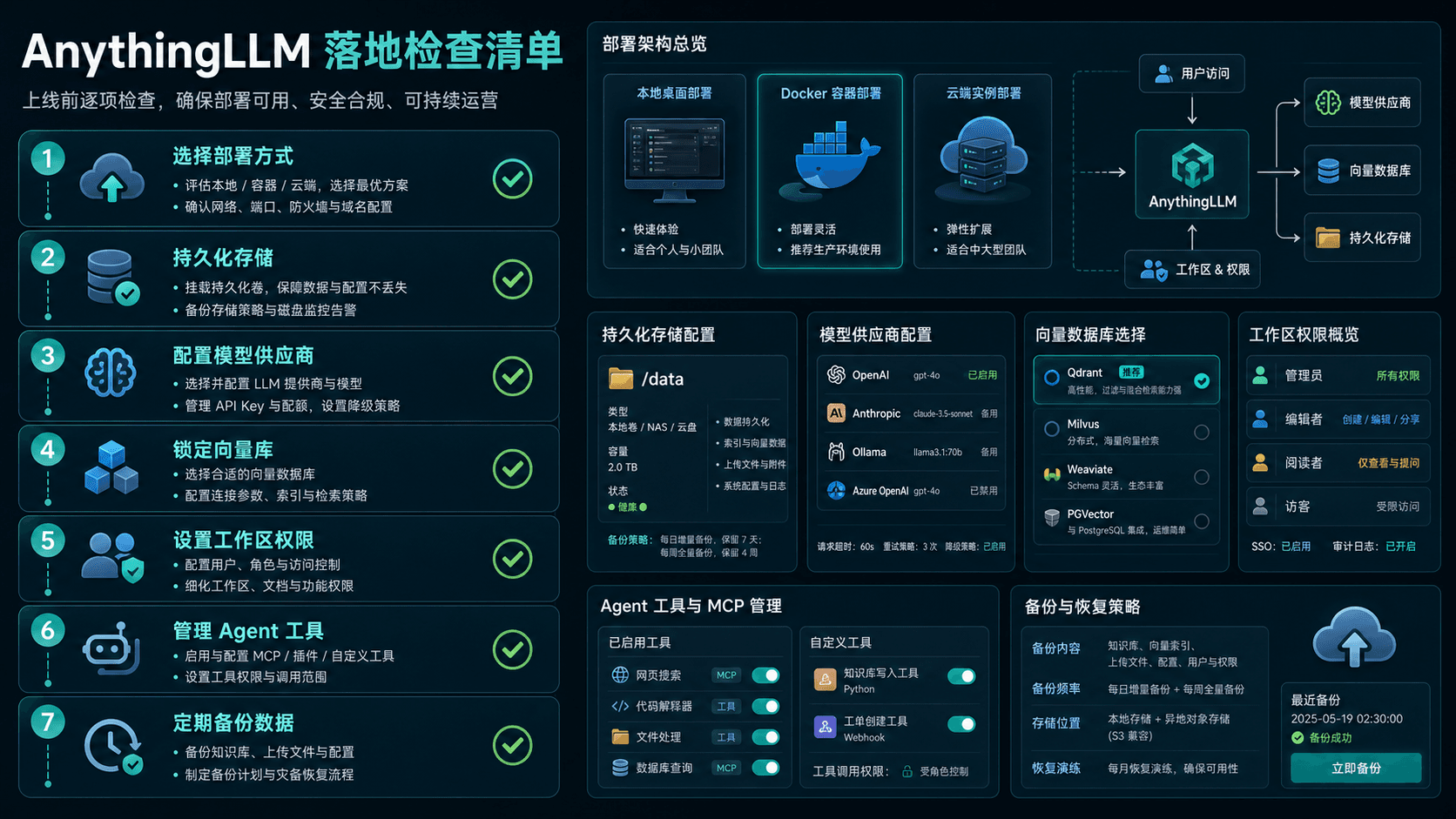
AnythingLLM 适合把文档、工作区、RAG 检索、Agent 工具和自部署选项放进同一套私有知识工作流。真正的难点不是上传资料后能聊天,而是工作区边界、引用复核、权限、备份和工具调用治理。
NBAI.club 编辑部

AnythingLLM:把私有知识库做成 AI 工作台,关键不是“能聊天”
很多团队第一次搭建知识库问答时,目标很简单:把 PDF、文档、网页和内部资料丢进去,然后让 AI 回答问题。这个目标听起来直接,但真正落地后会发现,难点不在“能不能聊”,而在于文档怎么组织、权限怎么控制、引用怎么复核、模型和向量库怎么选、Agent 工具能不能被安全使用。
AnythingLLM 的价值适合放在这个背景下理解。它不是单纯的聊天窗口,而是把工作区、文档索引、RAG 检索、模型供应商、向量数据库、Agent 能力和自部署选项放到一个相对完整的环境里。对希望掌控数据边界的团队来说,这比单纯接入一个云端 Chatbot 更接近真实工作流。
私有知识库不是“上传越多越好”
知识库问答最常见的误区,是把所有资料一次性导入,然后期待模型自动变聪明。现实恰好相反:文档越杂,回答越容易变得模糊。制度文件、产品手册、客户案例、会议纪要、FAQ、接口文档和销售话术如果混在一起,检索结果可能互相干扰。
AnythingLLM 的 Workspace 概念适合解决这个问题。一个工作区最好对应一个明确场景:客服 FAQ、产品文档、内部制度、研发知识库、销售资料、项目交付文档。这样做的好处是,检索范围更清晰,回答更容易附带可验证上下文,也更方便后续维护。
真正有效的私有知识库,应该先设计边界,再导入资料。先问清楚:谁会使用?解决什么问题?哪些文档是权威来源?哪些资料过期后必须下架?哪些内容只能特定成员访问?如果这些问题没有答案,RAG 很容易变成“高级全文搜索”,而不是可靠的工作台。